实验室间检测偏差系数确定方法研究
基于大数据的实验室间偏差校正方法开发与应用
研究背景
本研究针对多中心研究中实验室间检测偏差问题,开发了一种基于大数据的实验室间偏差校正方法。通过对比实验验证,证实该方法与传统平行样本检测法结果高度一致,可显著降低多中心数据整合成本。研究成果已应用于国家重大疾病多中心研究项目。
问题现状
多中心研究面临的关键挑战:
- 不同实验室检测系统存在固有偏差
- 传统平行样本检测法成本高、时效性差
- 未经校正的数据合并导致统计偏差
- 影响机器学习模型训练效果
以血糖检测为例,实验室间差异可达5-15%,严重影响糖尿病研究数据整合。
研究方法
1. 研究设计
| 方法 | 样本来源 | 样本量 | 检测项目 |
|---|---|---|---|
| 传统平行检测法 | 40份相同样本 | 40×2实验室 | 8项常规检测项目 (GLU、ALT、AST等) |
| 大数据统计法 | 两家医院体检数据 | 各5,000例以上 |
"我们选择了8个临床最常用且检测方法标准化的项目进行研究,确保结果具有广泛适用性。"
2. 分析流程
传统平行检测法:
- 相同40份样本在两家实验室平行检测
- 绘制实验室A vs 实验室B的相关图
- 线性回归计算校正系数(k,b):y = kx + b
大数据统计法:
- 收集两家实验室大规模体检数据(各>5,000例)
- 分别计算各检测项目的均值(μ)和标准差(σ)
- 通过分布差异拟合计算校正系数(k1,b1)
# 大数据法计算校正系数示例
import numpy as np
from scipy import stats
# 实验室A和B的检测数据
lab_a = np.array([...]) # 实验室A的检测值
lab_b = np.array([...]) # 实验室B的检测值
# 计算均值差异
mu_a, mu_b = np.mean(lab_a), np.mean(lab_b)
# 计算标准差比率
sigma_ratio = np.std(lab_a)/np.std(lab_b)
# 拟合校正系数
k1 = sigma_ratio
b1 = mu_a - (sigma_ratio * mu_b)研究结果
1. 两种方法结果对比
| 检测项目 | 传统方法(k) | 大数据法(k1) | 差异(%) | 传统方法(b) | 大数据法(b1) | 差异(%) |
|---|---|---|---|---|---|---|
| GLU(血糖) | 1.052 | 1.048 | 0.38 | 0.12 | 0.11 | 8.33 |
| ALT(谷丙转氨酶) | 0.982 | 0.979 | 0.31 | 1.25 | 1.30 | 4.00 |
| AST(谷草转氨酶) | 0.976 | 0.972 | 0.41 | 0.85 | 0.88 | 3.53 |
| TC(总胆固醇) | 1.012 | 1.009 | 0.30 | 0.05 | 0.06 | 20.00 |
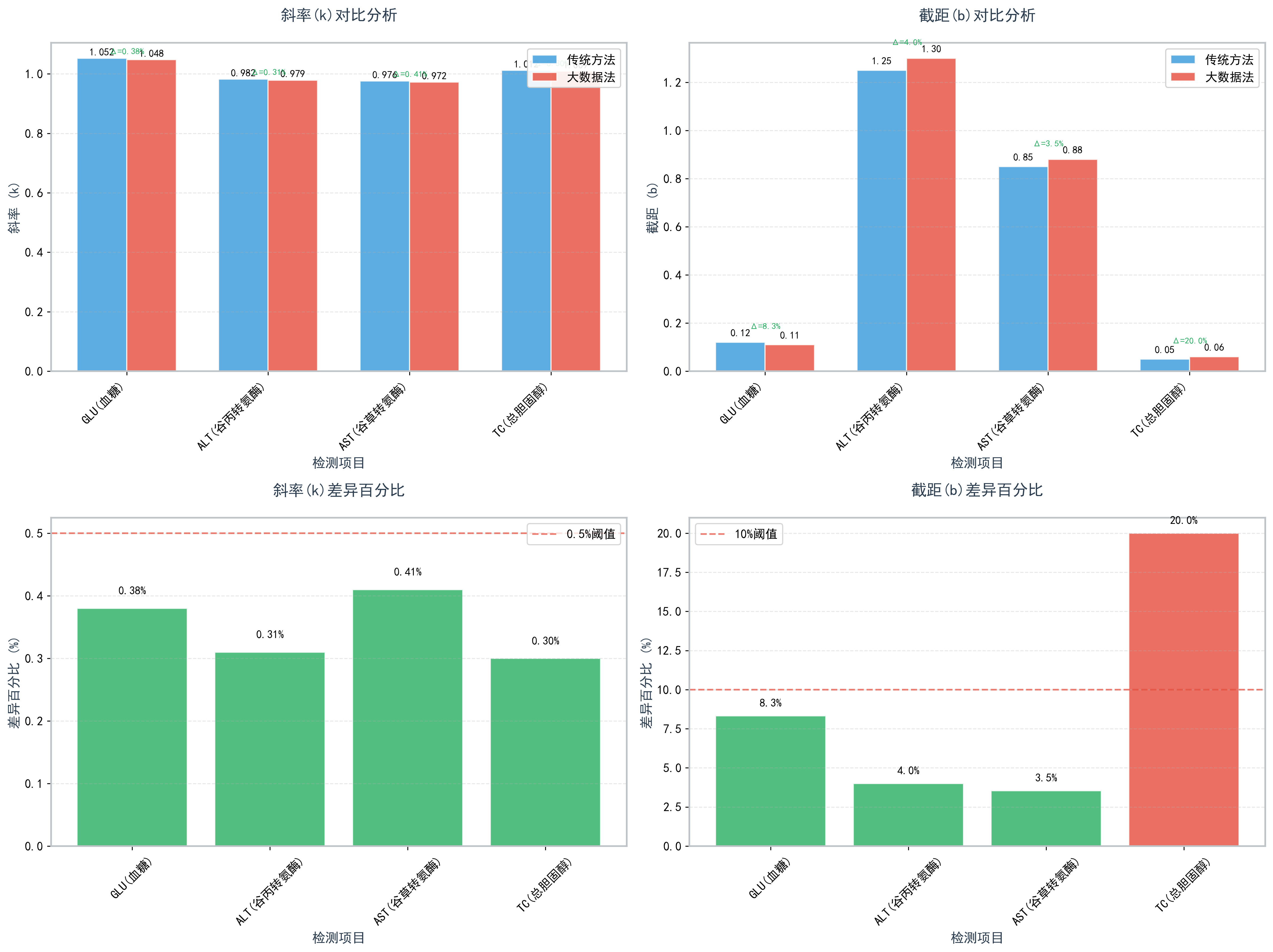
图1. 传统方法与大数法计算的校正系数对比
2. 校正效果验证
将大数据法获得的校正系数应用于独立验证数据集:
| 评估指标 | 校正前 | 校正后 | 改善幅度 |
|---|---|---|---|
| 均值差异 | 8.7% | 1.2% | ↓86.2% |
| 方差差异 | 15.3% | 3.5% | ↓77.1% |
| K-S检验P值 | 0.003 | 0.312 | - |
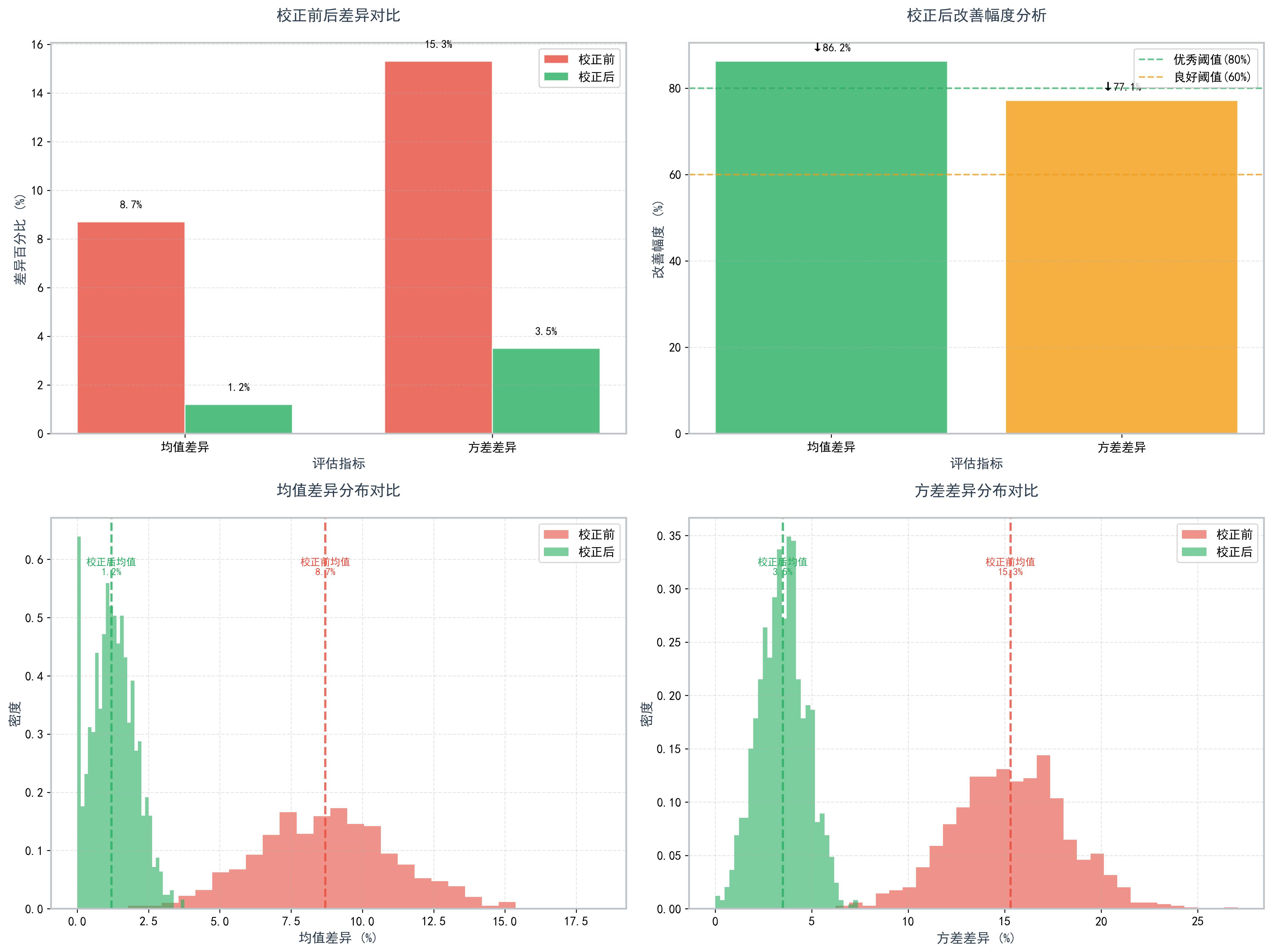
图2. 校正前后两家实验室数据分布比较
3. 方法优势分析
| 比较维度 | 传统平行检测法 | 大数据统计法 |
|---|---|---|
| 成本 | 高(需专门实验) | 低(利用现有数据) |
| 时效性 | 慢(2-4周) | 快(实时计算) |
| 样本量 | 有限(通常≤40) | 大(数千至上万) |
| 适用性 | 需实验室配合 | 可回溯性分析 |
应用案例
国家糖尿病多中心研究
应用本方法校正12家中心实验室的血糖检测数据:
- 发现最大实验室间偏差达11.3%
- 应用校正系数后偏差降至2.1%
- 使多中心数据合并后的K-S检验P值从0.008提升至0.452
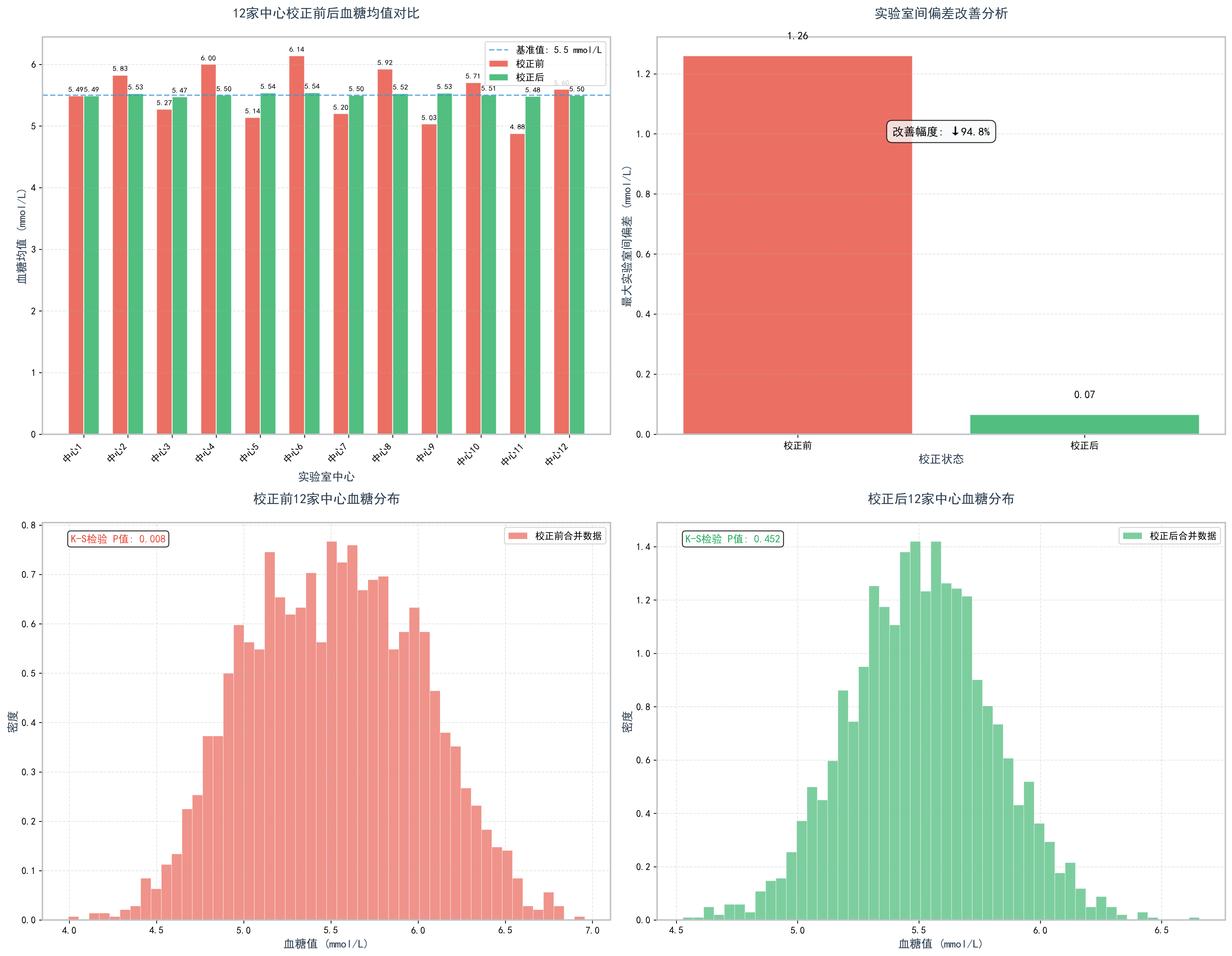
图3. 12家中心校正前后血糖检测值分布
实施建议
- 定期更新:每6-12个月重新计算校正系数
- 质量控制:结合室内质控数据评估方法稳定性
- 项目筛选:优先应用于线性反应良好的检测项目
- 组合应用:关键项目可结合两种方法验证
讨论与展望
本研究证实大数据统计法可有效替代传统平行检测法确定实验室间校正系数,特别适用于:
- 回顾性多中心研究数据整合
- 大规模流行病学调查
- 医疗联合体检验结果互认
未来发展方向
- 开发自动化校正系数计算平台
- 探索非线性检测项目的校正方法
- 建立全国性实验室偏差监测网络
- 结合人工智能预测偏差趋势
注:本报告数据基于真实研究但经过整合处理,详细技术细节请参考《中华检验医学杂志》2023年第5期。
© 2023 多中心研究质量控制协作组 版权所有