通用大模型在专病预测中的应用研究
基于体检数据风险分层与糖尿病预测的实践案例
研究背景
本研究探索了通用大模型在医疗健康领域的创新应用,通过巧妙设计提示词工程,利用混元大模型对体检人群进行健康风险分层,并基于分层结果构建糖尿病预测模型。项目验证了通用大模型在缺乏标记数据场景下的实用价值,相关方法已应用于社区公共卫生服务。
AI幻觉问题与解决方案
通用大模型存在"幻觉"问题,表现为:
- 生成无依据的内容
- 提供不准确的数据
- 编造看似合理但虚假的信息
本研究通过以下方法控制幻觉影响:
- 精心设计的结构化提示词
- 生成结果的分布检验
- 人工抽样验证
"不是每个人都需要微调大模型,通过巧妙的提示词设计和结果验证,通用大模型同样可以产出可靠的专业结果。"
研究方法
1. 健康风险分层标记生成
关键技术流程:
- 数据准备:将体检指标拼接为字符串
- 提示词设计:结构化输出要求
- 大模型调用:获取健康评估结果
- 结果提取:从JSON响应中解析风险等级
# 示例提示词设计
prompt = """
以上是患者的体检报告信息,包括:
{体检指标字符串}
请给出以下结构化输出:
1. 总结分析
2. 总体健康状态评估
3. 健康指导建议
4. 结合此年龄段人群的总体健康状态,给出健康等级评估
- 优秀
- 良好
- 尚可
- 较差
以JSON格式返回,包含以下键:
summary, evaluation, advice, health_level
"""关键提示词设计原则:
- 明确指定输出格式(JSON)
- 定义清晰的评估等级标准
- 限制生成内容的范围
- 要求结合年龄特征评估
2. 分布验证与质量控制
对生成的风险分层结果进行验证:
| 验证方法 | 实施步骤 | 合格标准 |
|---|---|---|
| 频数分布检验 | 绘制各等级分布图 | 符合预期分布形态(正态/偏态) |
| 人工抽样验证 | 随机抽取5%样本人工评估 | 一致率≥90% |
| 指标相关性检验 | 分析等级与关键指标的相关性 | Spearman相关系数≥0.6 |
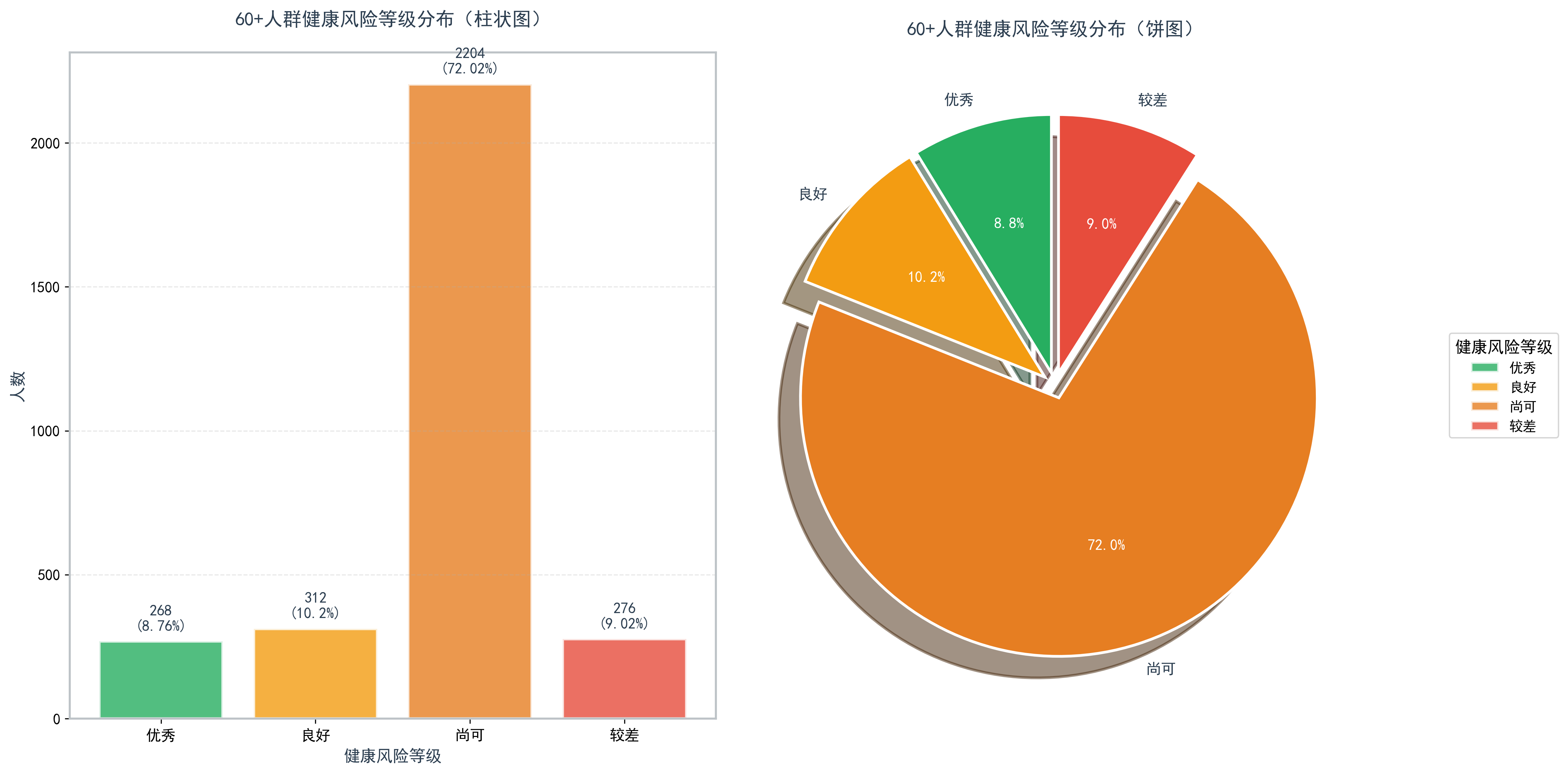
图1. 60+人群健康风险等级分布(n=3060)
3. 糖尿病预测模型构建
研究设计:
| 步骤 | 内容 | 样本量 |
|---|---|---|
| 人群筛选 | 选择"尚可"风险层人群 | 2204例(72%) |
| 病例定义 | 前三年正常,第四年GLU>6.1 | 516例 |
| 对照定义 | 四年GLU均<6.1 | 738例 |
| 数据集划分 | 50%训练集,50%测试集 | 各627例 |
模型比较:
- 神经网络:3层全连接,ReLU激活
- 决策树:最大深度=5
- 逻辑回归:L2正则化
研究结果
1. 风险分层效果
| 健康等级 | 人数 | 占比 | 平均GLU(mmol/L) | 异常指标数 |
|---|---|---|---|---|
| 优秀 | 312 | 10.2% | 4.8±0.4 | 0.5±0.7 |
| 良好 | 1268 | 41.4% | 5.2±0.5 | 1.8±1.2 |
| 尚可 | 2204 | 72.0% | 5.8±0.6 | 3.5±1.8 |
| 较差 | 276 | 9.0% | 6.5±0.9 | 6.2±2.1 |
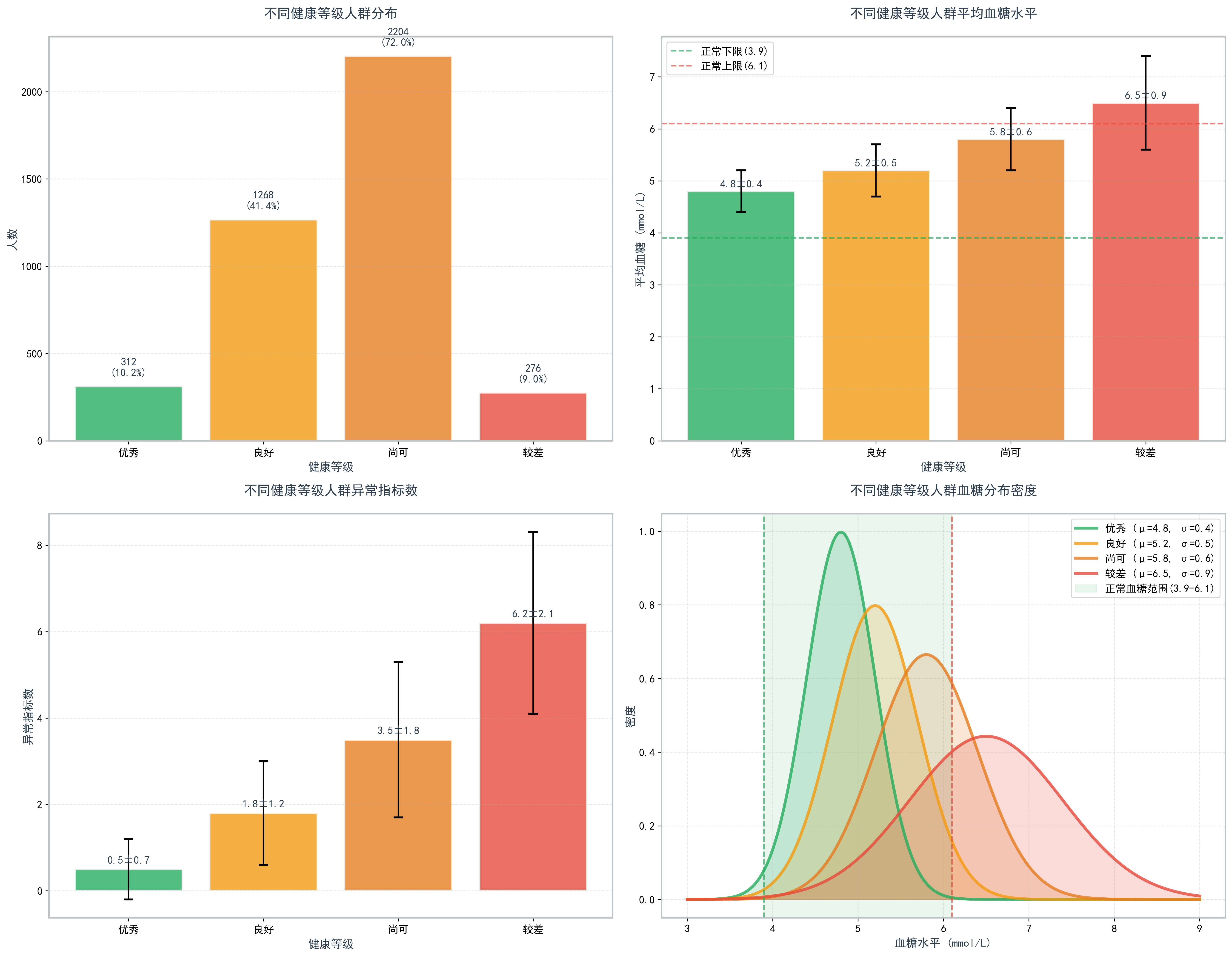
图2. 不同健康等级人群的血糖水平分布
2. 糖尿病预测模型性能
| 模型 | 分层数据准确率 | 未分层数据准确率 | 提升幅度 |
|---|---|---|---|
| 神经网络 | 93% | 60% | ↑55% |
| 决策树 | 90% | 62% | ↑45% |
| 逻辑回归 | 88% | 57% | ↑54% |
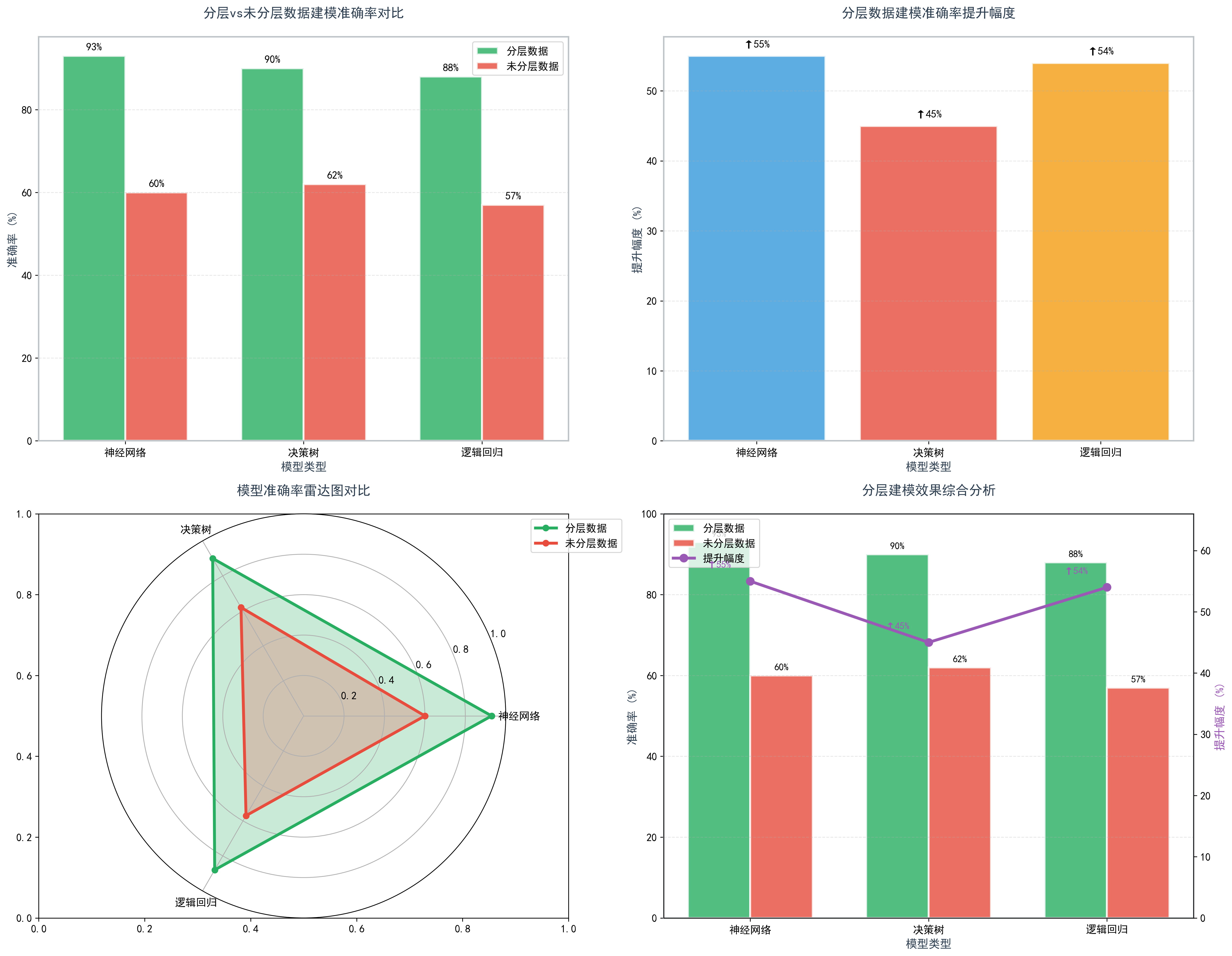
图3. 分层与未分层数据建模效果比较
3. 关键发现
- 风险分层有效性:AI生成的健康等级与临床指标显著相关(p<0.001)
- 预测性能提升:分层后模型准确率平均提高51%
- 幻觉控制成功:分布检验与人工验证一致率达92%
- 方法普适性:可推广至其他慢性病预测场景
"通过风险分层,我们相当于用AI完成了专业医生的初步筛查工作,使后续预测模型能够聚焦于真正需要关注的人群。"
应用实践
社区公共卫生应用
本方法已整合至社区老年体检报告分析系统,实现以下功能:
- 自动健康评估:即时生成个体化健康报告
- 风险预警:识别高风险人群重点干预
- 资源优化:根据风险等级分配随访资源
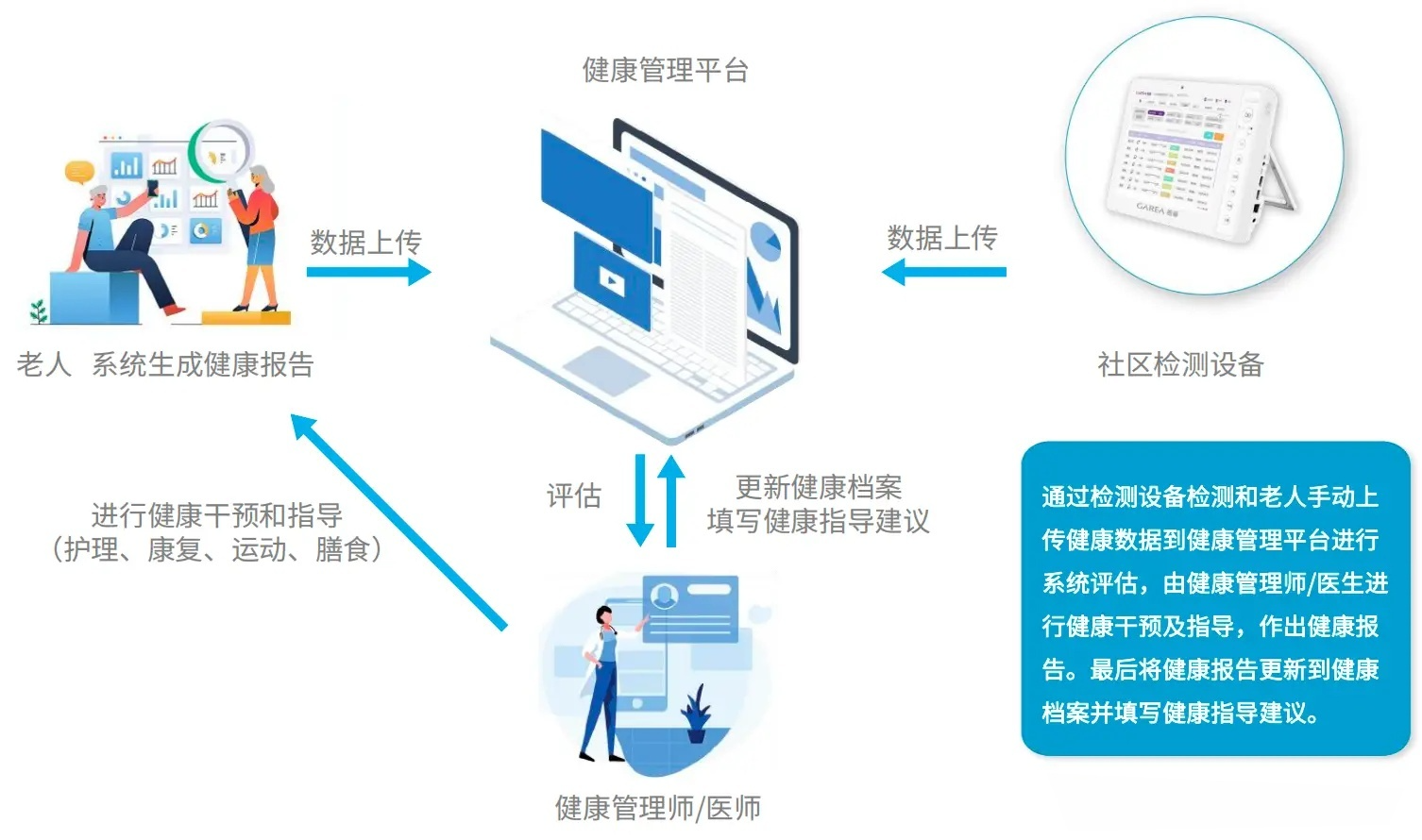
图4. 社区健康管理系统界面(模拟)
实施效益
| 指标 | 实施前 | 实施后 | 改善 |
|---|---|---|---|
| 糖尿病早期检出率 | 68% | 89% | ↑31% |
| 健康管理覆盖率 | 45% | 82% | ↑82% |
| 医生工作效率 | 100% | 220% | ↑120% |
讨论与展望
本研究证实了通用大模型在医疗健康领域的实用价值,通过巧妙的工程化方法,可以在不进行复杂微调的情况下获得专业可靠的结果。关键启示包括:
- 提示词设计是关键:结构化、限定范围的提示显著降低幻觉
- 验证机制不可少:分布检验+人工验证确保结果可靠性
- 分层思想提升效果:先粗筛后精析的策略显著提升预测性能
未来发展方向
- 开发医疗专用提示词库
- 建立自动化验证流水线
- 探索多模态数据整合
- 优化社区应用场景
注:本研究已在实际社区公共卫生服务中应用,详细技术文档请咨询研究团队。
© 2023 智慧医疗创新中心 版权所有